
นักวิจัยได้พัฒนา DarkBERT โมเดลภาษาที่ได้รับการฝึกฝนล่วงหน้าด้วยข้อมูลจากดาร์กเว็บ เพื่อช่วยผู้เชี่ยวชาญด้านความปลอดภัยสามารถดึงข้อมูลสำหรับ Cyber Threat Intelligence : CTI จากส่วนลึกของอินเทอร์เน็ตได้
DarkBERT : โมเดลภาษาสำหรับดาร์กเว็บ
เป็นเวลานานที่นักวิจัย และผู้เชี่ยวชาญด้านความปลอดภัยทางไซเบอร์ได้ใช้การประมวณผลแบบ Natural Language Processing : NLP เพื่อทำความเข้าใจ และจัดการกับขอบเขตของภัยคุกคาม โดย NLP เป็นส่วนสำคัญของการวิจัยเกี่ยวกับ CTI
ดาร์กเว็บเปรียบเหมือน "สนามเด็กเล่น" ของบุคคลที่เกี่ยวข้องกับกับพฤติกรรมที่ผิดกฏหมาย ซึ่งถือเป็นความท้าทายสำหรับการดึงข้อมูลดังกล่าวสำหรับการทำ CTI
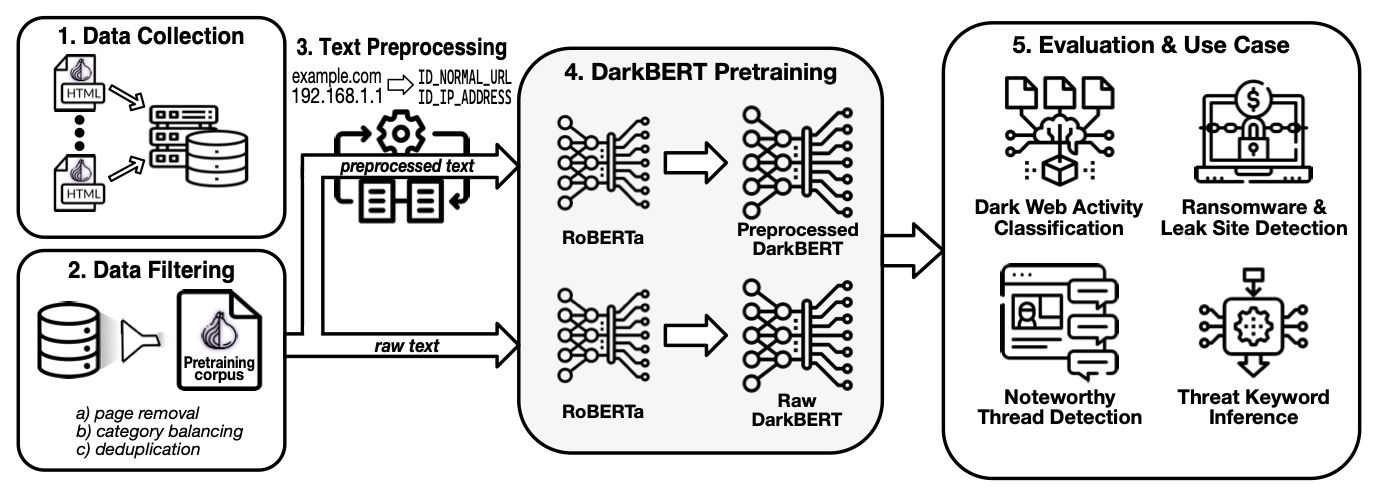
ทีมนักวิจัยจากสถาบันวิทยาศาสตร์ และเทคโนโลยีขั้นสูงของเกาหลี (Korea Advanced Institute of Science and Technology : KAIST) และบริษัท S2W (บริษัทข่าวกรองข้อมูลที่เชี่ยวชาญด้านข่าวกรองภัยคุกคามทางไซเบอร์ การละเมิดแบรนด์ดิจิดัล และบล็อกเชน) ได้ตัดสินใจทดสอบโมเดลภาษาที่ถูกฝึกมาแบบเฉพาะ DarkBERT ที่ได้รับการฝึกฝนล่วงหน้าด้วยข้อมูลของดาร์กเว็บ
สถานการณ์การใช้งานที่เป็นไปได้
DarkBERT ได้ผ่านการฝึกฝนล่วงหน้าอย่างครอบคลุมบนข้อความภาษาอังกฤษประมาณ 6.1 ล้านหน้าบนดาร์กเว็บ (โดยนักวิจัยกรองหน้าเว็บที่ไม่มีความหมาย และไม่เกี่ยวข้องออก) และถูกนำมาเปรียบเทียบประสิทธิภาพกับโมเดล NLP ยอดนิยมอีก 2 โมเดล ได้แก่ BERT ซึ่งเป็นโมเดล masked-language จาก google ในปี 2018 และ RoBERTa ที่เป็นวิธีการประมวลผล AI พัฒนาโดย Facebook ในปี 2019
นักวิจัยทดสอบ DarkBERT เพื่อใช้งานในกรณีที่เกี่ยวข้องกับความปลอดภัยในโลกไซเบอร์ 3 กรณี คือ
1. การตรวจจับเว็บไซต์ที่ปล่อยข้อมูลของเหยื่อที่โดน Ransomware
กลุ่ม Ransomware ใช้ดาร์กเว็บเพื่อสร้างเว็บไซต์ที่พวกเขาจะปล่อยข้อมูลขององค์กรที่ปฏิเสธการจ่ายค่าไถ่ โดยโมเดลภาษาทั้งสามได้รับมอบหมายให้ระบุ และจัดประเภทเว็บไซต์ดังกล่าว และ DrakBERT มีประสิทธิภาพดีกว่าโมเดลที่เหลือ ซึ่งแสดงให้เห็นถึงข้อดีในการทำความเข้าใจภาษาใน hacking forums บนดาร์กเว็บ
นักวิจัยระบุว่า DarkBERT ที่ได้รับข้อมูลที่ผ่านการประมวลผลมา ดีกว่าข้อมูลที่ไม่ได้รับการประมาณผล แสดงถึงความสำคัญของขั้นตอนก่อนการประมาณผลข้อความเพื่อลดข้อมูลที่ไม่จำเป็น
2. การตรวจจับเธรดที่น่าสนใจ
forums บนดาร์กเว็บมักถูกใช้เพื่อแลกเปลี่ยนข้อมูลที่ผิดกฎหมาย และบ่อยครั้งที่นักวิจัยด้านความปลอดภัยจะคอยตรวจสอบเธรดที่น่าสนใจเพื่อลดความเสี่ยงที่เกี่ยวข้องได้ แต่เนื่องจากมีจำนวน forums และ post forum จำนวนมาก ความสามารถในการค้นหา และประเมินความน่าสนใจของเธรดโดยอัตโนมัติสามารถช่วยลดภาระของงานได้อย่างมาก และอีกปัญหาหลักคือภาษาเฉพาะที่ใช้ในดาร์กเว็บ
นักวิจัยพบว่า เนื่องจากความยากลำบากของงานเอง ผลลัพธ์โดยรวมของ DarkBERT สำหรับการตรวจจับเธรดที่น่าสนใจในโลกความเป็นจริงยังไม่ดีเท่าเมื่อเทียบกับการประเมินก่อนหน้านี้ อย่างไรก็ตาม การแสดงผลของ DarkBERT ยังคงเหนือกว่าโมเดลภาษาอื่น ๆ เป็นอย่างมากในงานด้านดาร์กเว็บ ซึ่งเชื่อว่าการเพิ่มตัวอย่างในการฝึกฝน และพัฒนา features เพิ่มเติม เช่น ข้อมูลผู้เขียน สามารถปรับปรุงประสิทธิภาพการตรวจจับให้ดียิ่งขึ้น
3.การอนุมาน Keyword ที่เป็นภัยคุกคาม
นักวิจัยใช้ฟังก์ชั่น Fill-mask เพื่อระบุ Keywords ที่เกี่ยวข้องกับภัยคุกคาม และการขายยาในดาร์กเว็บ ซึ่ง Fill-mask เป็นฟังก์ชันหลักของโมเดลภาษาตระกูล BERT ซึ่งจะค้นหาคำที่เหมาะสมที่สุดกับตำแหน่งที่ถูกซ่อนไว้ของประโยค ซึ่งมีประโยชน์ในการบันทึกว่า Keywords ใดเป็นตัวบ่งชี้ว่าถูกใช้ในการโจมตีจริง
โดยผลลัพธ์ของ DarkBERT ในการทดสอบแบบเฉพาะนี้ดีกว่าการทดสอบผลการทดสอบอื่น ๆ
ข้อสรุป
นักวิจัยพบว่า DarkBERT มีประสิทธิภาพสูงกว่าโมเดลภาษาอื่นในทุกงานที่นำเสนอ อย่างไรก็ตามจำเป็นต้องมีการปรับแต่งเพิ่มเติม เพื่อเพิ่มประสิทธิภาพมากขึ้นในการใช้งานที่หลากหลาย
นักวิจัยระบุเพิ่มเติมว่า "ในอนาคต มีการวางแผนปรับปรุงประสิทธิภาพของโมเดลภาษาที่ผ่านการฝึกล่วงหน้าในโดเมนดาร์กเว็บโดยใช้สถาปัตกรรมล่าสุด และเก็บรวบรวมข้อมูลเพิ่มเติมเพื่อสร้างโมเดลภาษาหลากหลายภาษาได้"
ที่มา: https://www.helpnetsecurity.com/2023/05/19/cti-dark-web/
You must be logged in to post a comment.